
02 Store Eda Input
![]()
상가(상권)정보 분석하기¶
- 데이터 출처 : 공공데이터포털
- 소상공인 상권정보 상가업소 데이터
- 영상에 사용한 데이터셋 다운로드 : http://bit.ly/open-data-set-folder
데이터셋을 엑셀에서 열어보는 방법¶
MS엑셀(Excel)에서 UTF-8로 된 CSV파일 불러오기
◦ 기존 euc-kr 데이터 추출형식으로 인해 업소명 오류가 발견되었으며 이를 개선하고자 UTF-8 형식으로 추출하였습니다.
◦ 개발자가 아닌 일반사용자의 경우 euc-kr(UTF-8 이나 UTF-16)이 아닌 CSV파일을 엑셀에서 바로 열면 한글이 모두 깨지게 됩니다.
◦ 바로 열지 마시고 다음 절차를 거치시기 바랍니다.
- 엑셀을 실행하고 데이터 → 텍스트를 선택합니다.
- 가져올 파일을 선택하고 확인을 클릭합니다.
- 콤보 박스에서 적절한 코드 타입이 선택됐는지 확인합니다.
* UTF-8의 코드 페이지 넘버는 65001입니다.
- 원본 데이터 파일 유형을 ‘구분 기호로 분리됨’ 선택합니다.
- 기타 ‘|’(파이프) 입력, 3단계 텍스트로 선택합니다.
* 단, 지번코드, 건물관리번호, 신우편번호, 경도, 위도 등 행마다 텍스트 선택
```
### 데이터셋 분류 지역
* 이 튜토리얼에서는 1번 파일만 사용합니다.※ 파일데이터 분류 지역 1 : 서울, 부산 2 : 대구, 인천, 광주, 대전, 울산 3 : 경기, 강원, 충북 4 : 충남, 전북, 전남, 경북, 경남, 제주 ```
라이브러리 로드¶
In [1]:
# 라이브러리를 로드합니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
In [2]:
from google.colab import drive
drive.mount('/content/drive')
한글폰트 설정¶
In [3]:
# 최근 데이터 시각화하기
# 그래프 한글폰트 사용설정 in Colab
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
%config InlineBackend.figure_format = 'retina'
!apt -qq -y install fonts-nanum
fontpath = '/content/drive/My Drive/파이썬/NanumGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
plt.rc('font', family='NanumBarunGothic')
mpl.font_manager._rebuild()
## Test
plt.figure(figsize=(3,3))
plt.text(0.5, 0.5, '한글 폰트 테스트 성공!!!', size=15)
plt.show()

파일로드¶
In [4]:
# 파일을 로드합니다.
df = pd.read_csv('/content/drive/MyDrive/데이터파일/상가업소정보_201912_01.csv', sep='|')
df.shape
Out[4]:
In [5]:
# 모든 컬럼이 표시되도록 max_columns 의 수를 지정합니다.
pd.options.display.max_columns = 39
In [6]:
# head 로 미리보기를 합니다.
df.head(1)
Out[6]:
In [7]:
# tail 로 미리보기를 합니다.
df.tail(1)
Out[7]:
인덱스 정보 보기¶
In [8]:
df.index
Out[8]:
컬럼명만 보기¶
In [9]:
# 컬럼값만 보기
df.columns
Out[9]:
info¶
In [10]:
# info 로 데이터프레임의 정보보기
df.info()
데이터 타입 보기¶
In [11]:
df.dtypes
Out[11]:
결측치 확인하기¶
In [12]:
df.isna().sum()
Out[12]:
In [13]:
# 결측치를 구해서 n 이라는 변수에 담고 재사용 합니다.
n = df.isna().sum()
결측치 시각화¶
In [14]:
# 막대그래프로 시각화 합니다.
plt.figure(figsize=(10,3))
n.plot.bar()
Out[14]:

In [15]:
# 값을 정렬해서 결측치가 많은 값이 위에 그려지도록 barh로 그립니다.
n.sort_values().plot.barh(figsize=(7, 8))
Out[15]:

missingno 로 결측치 시각화 하기¶
- 별도의 설치가 필요한 라이브러리 입니다.
- ResidentMario/missingno: Missing data visualization module for Python.
- 주피터 노트북 상에서 설치가 되지 않으니 anaconda prompt 를 열어서 설치해 주세요.
- 윈도우
- 관리자 권한으로 아나콘다를 설치하셨다면 다음의 방법으로 anaconda prompt 를 열어 주세요.

- 관리자 권한으로 아나콘다를 설치하셨다면 다음의 방법으로 anaconda prompt 를 열어 주세요.
- 맥
- terminal 프로그램을 열어 설치해 주세요.
- 아나콘다에서 설치(다음 3가지 중 하나의 명령어를 사용)
- conda install -c conda-forge missingno
- conda install -c conda-forge/label/gcc7 missingno
- conda install -c conda-forge/label/cf201901 missingno
In [16]:
# !pip install missingno
import missingno as msno
msno.matrix(df)
Out[16]:

In [17]:
# heatmap 으로 표현합니다.
msno.heatmap(df)
Out[17]:

In [18]:
# dendrogram 으로 표현합니다.
msno.dendrogram(df)
Out[18]:

사용하지 않는 컬럼 제거하기¶
결측치가 너무 많은 컬럼 제거하기¶
In [19]:
# sort_values 를 통해 결측치가 많은 데이터를 위에서 9개 가져와서 not_use 변수에 담습니다.
# not_use 변수에 담긴 인덱스값만 추출해서 not_use_col 이라는 변수에 담습니다.
not_use = n.sort_values(ascending=False).head(9)
not_use_col = not_use.index
not_use_col
Out[19]:
In [20]:
# 사용하지 않는 컬럼을 제거하고 잘 제거가 되었는지 shape 의 수로 확인합니다.
print(df.shape)
df = df.drop(not_use_col, axis=1)
df.shape
Out[20]:
In [21]:
# info()를 통해 해당 컬럼이 제거되었는지 확인하며 메모리 사용량이 줄어들었는지 확인합니다.
df.info()
사용하지 않는 컬럼 제거하기¶
In [22]:
# 컬럼명을 전처리 하기 위해 cols 라는 변수에 담습니다.
cols = df.columns
cols
Out[22]:
In [23]:
# 컬럼명에 "코드", "번호"가 있지만 이번 분석에서는 사용하지 않기 때문에
# 해당되는 컬럼만 찾아와서 cols_code 라는 변수에 담습니다.
cols_code = cols[cols.str.contains("코드|번호")]
cols_code
Out[23]:
In [24]:
# "코드", "번호" 가 들어가는 컬럼명만 drop으로 데이터프레임에서 제거합니다.
# 제거 전 후에 shape를 통해 컬럼이 삭제되었는지 확인합니다.
print(df.shape)
df = df.drop(cols_code, axis=1)
print(df.shape)
In [25]:
# info를 통해 컬럼정보와 메모리 사용량 등을 확인합니다.
df.info()
행, 열을 기준으로 값을 가져오기¶
열(column)기준¶
- df[열이름]
- 결과가 Pandas 의 Series 형태로 반환
- df[[열목록]] : 2개 이상의 열을 가져올 때는 리스트 형태로 묶어서 지정해주어야 합니다.
- 결과가 Pandas 의 DataFrame 형태로 반환
- 1개의 열을 2차원 리스트로 지정할 때에도 DataFrame 형태로 반환이 됩니다.
In [26]:
# "상호명" 컬럼만 가져옵니다.
df["상호명"].head()
Out[26]:
In [27]:
# "상호명", "도로명주소" 2개의 컬럼을 가져옵니다.
df[["상호명", "도로명주소"]].head()
Out[27]:
행(row) 기준¶
- df.loc[행]
- df.loc[행, 열]
- df.loc[행이름 혹은 번호]
- 결과가 Pandas 의 Series 형태로 반환
- df.loc[[행목록]] : 2개 이상의 행을 가져올 때는 열(column)을 가져올 때와 마찬가지로 리스트 형태로 묶어서 지정해주어야 합니다.
- 결과가 Pandas 의 DataFrame 형태로 반환
- 1개의 행을 2차원 리스트로 지정할 때에도 DataFrame 형태로 반환이 됩니다.
In [28]:
# 0 번째 인덱스 행을 가져옵니다.
df.loc[0]
Out[28]:
In [29]:
# 0, 1,2 번째 인덱스 행을 가져옵니다.
df.loc[[0,1,2]]
Out[29]:
In [30]:
# 0번째 행의 "상호명"을 가져옵니다.
# df.loc[0]["상호명"]
df.loc[0, "상호명"]
Out[30]:
In [31]:
# 0, 1, 2 번째 행의 "상호명"을 가져옵니다.
df.loc[[0,1,2], "상호명"]
Out[31]:
In [32]:
# 0, 1, 2 번째 행의 "상호명", "도로명주소"를 가져옵니다.
df.loc[[0,1,2], ["상호명", "도로명주소"]]
Out[32]:
iloc 로 슬라이싱을 통해 가져오기¶
- df.iloc[:] 전체 데이터를 가져옵니다.
- df.iloc[행, 열] 순으로 인덱스 번호를 지정합니다.
- : 은 전체를 의미합니다.
- 시작인덱스:끝나는인덱스+1을 써줍니다.
- 예) 3:5 라면 3번째 인덱스 부터 4번째 인덱스까지 가져옵니다.
- : 에서 앞이나 뒤 인덱스를 써주지 않으면 처음부터 혹은 끝까지를 의미합니다.
- 예) :5 => 처음부터 4번 인덱스까지 가져옵니다.
- 예) 5: => 5번 인덱스부터 끝까지 가져옵니다.
- 예) -5: => 뒤에서 5번째 부터 끝까지 가져옵니다.
- 예) :-5 => 처음부터 5번째 전까지 가져옵니다.
In [33]:
# 위에서 5개의 행과, 왼쪽에서 5개의 열을 가져옵니다.
df.iloc[:5, :5]
Out[33]:
In [34]:
# 끝에서 5개의 행과, 오른쪽에서 5개의 열을 가져옵니다.
df.iloc[-5:, -5:]
Out[34]:
기술통계 값 보기¶
describe 로 요약하기¶
- describe 를 사용하면 데이터를 요약해 볼 수 있습니다.
- 기본적으로 수치형 데이터를 요약해서 보여줍니다.
- include, exclude 옵션으로 데이터 타입에 따른 요약수치를 볼 수 있습니다.
- 데이터의 갯수, 평균, 표준편차, 최솟값, 1사분위수(25%), 2사분위수(50%), 3사분위수(75%), 최댓값을 볼 수 있습니다.
- Descriptive statistics - Wikipedia
In [35]:
# describe 로 기술통계값을 봅니다.
# DataFrame.count: Count number of non-NA/null observations.
# DataFrame.max: Maximum of the values in the object.
# DataFrame.min: Minimum of the values in the object.
# DataFrame.mean: Mean of the values.
# DataFrame.std: Standard deviation of the observations.
# DataFrame.select_dtypes: Subset of a DataFrame including/excluding
# columns based on their dtype.
df.describe()
Out[35]:
In [36]:
# 필요한 컬럼에 대한 요약만 봅니다.
# 위도, 경도 만 따로 가져와 요약합니다.
df[["위도", "경도"]].describe()
Out[36]:
개별 기술통계 값 구하기¶
count 결측치를 제외한 (NaN이 아닌) 값의 갯수를 계산
- min, max 최솟값, 최댓값
- argmin, argmax 최솟값, 최댓값이 위치한 (정수)인덱스를 반환
- idxmin, idxmax 인덱스 중 최솟값, 최댓값을 반환
- quantile 특정 사분위수에 해당하는 값을 반환 (0~1 사이)
- 0.25 : 1사분위 수
- 0.5 : 2사분위수 (quantile 의 기본 값)
- 0.75 : 3사분위수
- sum 수치 데이터의 합계
- mean 평균
- median 중앙값(중간값:데이터를 한 줄로 세웠을 때 가운데 위치하는 값, 중앙값이 짝수일 때는 가운데 2개 값의 평균을 구함)
- mad 평균값으로부터의 절대 편차(absolute deviation)의 평균
- std, var 표준편차, 분산을 계산
- cumsum 맨 첫 번째 성분부터 각 성분까지의 누적합을 계산 (0 번째 부터 계속 더해짐)
- cumprod 맨 첫번째 성분부터 각 성분까지의 누적곱을 계산 (1 번째 부터 계속 곱해짐)
In [37]:
# 결측치를 제외한 (NaN이 아닌) 값의 갯수를 계산
df["위도"].count()
Out[37]:
In [38]:
# 평균
df["위도"].mean()
Out[38]:
In [39]:
# 최댓값
df["위도"].max()
Out[39]:
In [40]:
# 최솟값
df["위도"].min()
Out[40]:
In [41]:
# 1사분위 수(25%)
df["위도"].quantile(q=0.25)
Out[41]:
In [42]:
# 2사분위 수(25%) == 중앙값
df["위도"].quantile()
Out[42]:
In [43]:
# 중앙값
df["위도"].median()
Out[43]:
In [44]:
# 중앙값 vs 평균값
print(df["위도"].median())
df["위도"].mean()
Out[44]:
In [45]:
# 분산
df["위도"].var()
Out[45]:
표준 편차(標準 偏差, 영어: standard deviation)는 자료의 산포도를 나타내는 수치로, 분산의 양의 제곱근으로 정의된다. 표준편차가 작을수록 평균값에서 변량들의 거리가 가깝다.[1] 통계학과 확률에서 주로 확률의 분포, 확률변수 혹은 측정된 인구나 중복집합을 나타낸다. 일반적으로 모집단의 표준편차는 {\displaystyle \sigma }\sigma (시그마)로, 표본의 표준편차는 {\displaystyle S}S(에스)로 나타낸다.[출처 필요]
편차(deviation)는 관측값에서 평균 또는 중앙값을 뺀 것이다.
분산(variance)은 관측값에서 평균을 뺀 값을 제곱하고, 그것을 모두 더한 후 전체 개수로 나눠서 구한다. 즉, 차이값의 제곱의 평균이다. 관측값에서 평균을 뺀 값인 편차를 모두 더하면 0이 나오므로 제곱해서 더한다.
표준 편차(standard deviation)는 분산을 제곱근한 것이다. 제곱해서 값이 부풀려진 분산을 제곱근해서 다시 원래 크기로 만들어준다.
In [46]:
# 표준편차 => 분산에 root 를 씌운 값입니다.
df["위도"].std()
Out[46]:
In [47]:
import numpy as np
np.sqrt(df["위도"].var())
Out[47]:
단변량 수치형 변수 시각화¶
In [48]:
# 위도의 distplot 을 그립니다.
sns.distplot(df["위도"])
Out[48]:

In [49]:
# 경도의 distplot 을 그립니다.
sns.distplot(df["경도"])
Out[49]:

In [50]:
# 위도의 평균, 중앙값을 표현하고 color로 선의 색상을 linestyle 로 점선으로 표시해 봅니다.
plt.axvline(df["위도"].mean(), linestyle = ":", color="r")
plt.axvline(df["위도"].median(), linestyle = "--")
sns.distplot(df["위도"])
Out[50]:

상관계수¶
- 상관 분석 - 위키백과, 우리 모두의 백과사전
- r 값은 X 와 Y 가 완전히 동일하면 +1, 전혀 다르면 0, 반대방향으로 완전히 동일 하면 –1 을 가진다.
- 결정계수(coefficient of determination) 는 r ** 2 로 계산하며 이것은 X 로부터 Y 를 예측할 수 있는 정도를 의미한다.
- r이 -1.0과 -0.7 사이이면, 강한 음적 선형관계,
- r이 -0.7과 -0.3 사이이면, 뚜렷한 음적 선형관계,
- r이 -0.3과 -0.1 사이이면, 약한 음적 선형관계,
- r이 -0.1과 +0.1 사이이면, 거의 무시될 수 있는 선형관계,
- r이 +0.1과 +0.3 사이이면, 약한 양적 선형관계,
- r이 +0.3과 +0.7 사이이면, 뚜렷한 양적 선형관계,
- r이 +0.7과 +1.0 사이이면, 강한 양적 선형관계

In [51]:
# 각 변수의 상관계수를 구합니다.
corr = df.corr()
corr
Out[51]:
In [52]:
# 위에서 구한 상관계수를 시각화 합니다.
# annot = 상관계수깂 표시 / cmap = 색상 / mask로 왼쪽 삼각형만 표시
mask = np.triu(np.ones_like(corr, dtype=np.bool))
sns.heatmap(corr,annot=True, cmap="Blues", mask=mask)
Out[52]:

산점도로 이변량 수치형 변수 표현하기¶
In [53]:
# scatterplot 으로 경도와 위도를 표현하며,
# 데이터의 갯수가 많으면 오래 걸리기 때문에 1000 개의 샘플을 추출해서 그립니다.
sns.scatterplot(data=df.sample(1000), x="경도", y="위도",)
Out[53]:

In [54]:
# 위 시각화에서 회귀선을 그립니다.
sns.regplot(data=df.sample(1000), x = "경도", y = "위도")
Out[54]:

In [55]:
# 회귀선을 그리는 그래프의 서브플롯을 그립니다.
# col = 값 별로 다르게 보기 / fit_reg = 회귀선 그리기)
sns.lmplot(data=df.sample(1000), x="경도", y="위도", hue="시도명", col="시도명", fit_reg=True)
Out[55]:

object 타입의 데이터 요약하기¶
In [56]:
# include="object" 로 문자열 데이터에 대한 요약을 봅니다.
df.describe(include="object")
Out[56]:
In [57]:
# 상권업종대분류명 의 요약값을 봅니다.
df["상권업종대분류명"].describe()
Out[57]:
In [58]:
# 상권업종대분류명 의 unique 값을 봅니다.
df["상권업종대분류명"].unique()
Out[58]:
In [59]:
# 상권업종대분류명 의 unique 값의 갯수를 세어봅니다.
df["상권업종대분류명"].nunique()
Out[59]:
In [60]:
df["상권업종대분류명"].mode()
Out[60]:
범주형 변수의 빈도수 구하기¶
In [61]:
# value_counts 로 상권업종대분류명 의 빈도수를 구합니다.
df["상권업종대분류명"].value_counts()
Out[61]:
인덱싱과 필터로 서브셋 만들기¶
In [62]:
# "상권업종대분류명" 이 "음식인 데이터만 가져오기
# df_food 라는 변수에 담아줍니다. 서브셋을 새로운 변수에 저장할 때 copy()를 사용하는 것을 권장합니다.
df_food = df[df["상권업종대분류명"] == "음식"].copy()
df_food.head()
Out[62]:
강남구의 상권업종대분류가 음식만 보기¶
In [63]:
# 시군구명이 "강남구" 인 데이터만 가져옵니다.
df[df["시군구명"] == "강남구"].head()
Out[63]:
In [64]:
# 이번에는 시군구명이 "강남구" 이고 "상권업종대분류명" 이 "음식"인 서브셋을 가져온 후
# "상권업종중분류명" 별로 빈도수를 구합니다.
df[(df["시군구명"] == "강남구") &
(df["상권업종대분류명"] == "음식")]["상권업종중분류명"].value_counts()
Out[64]:
In [65]:
# 위와 똑같이 구하지만 이번에는 loc를 사용합니다.
# loc[행, 열]
df.loc[(df["시군구명"] == "강남구") & (df["상권업종대분류명"] == "음식"),
"상권업종중분류명"].value_counts()
Out[65]:
구별 음식점 업종 비교하기¶
In [66]:
# df_seoul_food 에 "시도명"이 "서울특별시" 이고 "상권업종대분류명" 이 "음식" 에 대한 서브셋만 가져와서 담아줍니다.
df_seoul_food = df[(df["시도명"] == "서울특별시") & (df["상권업종대분류명"] == "음식")].copy()
df_seoul_food.shape
Out[66]:
In [67]:
# "시군구명", "상권업종중분류명" 으로 그룹화 해서 상점수를 세어봅니다.
# 결과를 food_gu 에 담아 재사용할 예정입니다.
food_gu = df_seoul_food.groupby(["시군구명", "상권업종중분류명"])["상호명"].count()
food_gu.head()
Out[67]:
In [68]:
food_gu.unstack().iloc[:5, :5]
Out[68]:
In [69]:
# food_gu 에 담긴 데이터를 시각화 합니다.
# 상권업종중분류명 과 상점수 로 barplot을 그립니다.
food_gu.unstack().loc["강남구"].plot.bar()
Out[69]:

In [70]:
food = food_gu.reset_index()
food = food.rename(columns={"상호명":"상호수"})
food.head()
Out[70]:
In [71]:
plt.figure(figsize=(15, 4))
sns.barplot(data=food, x="상권업종중분류명", y="상호수")
Out[71]:

In [72]:
# catplot을 사용하여 서브프롯을 그립니다.
sns.catplot(data=food, x="시군구명", y="상호수",
kind="bar", col="상권업종중분류명", col_wrap=4)
Out[72]:

구별 학원수 비교¶
- 주거나 입지로 문화시설이나 학원, 교육 등을 고려하게 됩니다.
- 사교육이 발달한 지역으로 대치동이나 목동을 꼽는데 이 지역에 학원이 많이 분포 되어 있는지 알아봅니다.
서브셋 만들고 집계하기¶
In [73]:
# 학원의 분류명을 알아보기 위해 "상권업종대분류명"의 unique 값을 추출합니다.
df["상권업종대분류명"].unique()
Out[73]:
In [74]:
# "시도명"이 "서울특별시"이고 "상권업종대분류명"이 "학문/교육" 인 데이터를 서브셋으로 가져옵니다.
# 재사용을 위해 서브셋을 df_academy 에 저장합니다.
df_academy = df[(df["시도명"] == "서울특별시") & (df["상권업종대분류명"] == "학문/교육")].copy()
df_academy.head()
Out[74]:
In [75]:
# df_academy 에서 "상호명"으로 빈도수를 구합니다.
df_academy["상호명"].value_counts().head(10)
Out[75]:
In [76]:
# "시군구명" 으로 빈도수를 구합니다.
df_academy["시군구명"].value_counts()
Out[76]:
In [77]:
# "상권업종소분류명"으로 빈도수를 구하고 위에서 30개만 봅니다.
academy_count = df_academy["상권업종소분류명"].value_counts().head(30)
academy_count
Out[77]:
In [78]:
# "상권업종소분류명"으로 빈도수를 구하고
# 빈도수가 1000개 이상인 데이터만 따로 봅니다.
academy_count_1000 = academy_count[academy_count > 1000]
academy_count_1000
Out[78]:
In [79]:
# "시군구명", "상권업종소분류명" 으로 그룹화를 하고 "상호명"으로 빈도수를 계산합니다.
g_academy = df_academy.groupby(["시군구명", "상권업종소분류명"])["상호명"].count()
g_academy = g_academy.reset_index()
g_academy.columns = ["시군구명", "상권업종소분류명", "상호수"]
g_academy.head()
Out[79]:
seaborn으로 시각화 하기¶
In [80]:
# 위에서 구한 결과를 시군구명, 상호수로 barplot을 그립니다.
plt.figure(figsize=(15,4))
sns.barplot(data = g_academy, x="시군구명", y="상호수")
Out[80]:

isin 을 사용해 서브셋 만들기¶
- 상권업종소분류명을 빈도수로 계산했을 때 1000개 이상인 데이터만 가져와서 봅니다.
In [81]:
academy_count_1000.index
Out[81]:
In [82]:
# isin 으로 빈도수로 계산했을 때 1000개 이상인 데이터만 가져와서 봅니다.
# 서브셋을 df_academy_selected 에 저장합니다.
print(df_academy.shape)
df_academy_selected = df_academy[
df_academy["상권업종소분류명"].isin(academy_count_1000.index)].copy()
df_academy_selected.shape
Out[82]:
In [83]:
df_academy_selected["상권업종소분류명"].value_counts()
Out[83]:
In [84]:
# df_academy_selected 의 "시군구명"으로 빈도수를 셉니다.
df_academy_selected["시군구명"].value_counts()
Out[84]:
In [85]:
df_academy_selected.loc[
df_academy_selected["법정동명"] == "대치동",
"상권업종소분류명"].value_counts()
Out[85]:
In [86]:
df_academy_selected.loc[
df_academy_selected["법정동명"] == "목동",
"상권업종소분류명"].value_counts()
Out[86]:
In [87]:
# df_academy_selected 로 위에서 했던 그룹화를 복습해 봅니다.
# "상권업종소분류명", "시군구명" 으로 그룹화를 하고 "상호명"으로 빈도수를 계산합니다.
# g 라는 변수에 담아 재사용 할 예정입니다.
g = df_academy_selected.groupby(["상권업종소분류명", "시군구명"])["상호명"].count()
g
Out[87]:
Pandas 의 plot 으로 시각화¶
In [88]:
# 상권업종소분류명이 index 로 되어 있습니다.
# loc를 통해 index 값을 가져올 수 있습니다.
# 그룹화된 결과 중 "학원-입시" 데이터만 가져옵니다.
g.loc["학원-입시"].sort_values().plot.barh(figsize=(10, 7))
Out[88]:

In [89]:
# 그룹화된 데이터를 시각화 하게 되면 멀티인덱스 값으로 표현이 되어 보기가 어렵습니다.
# 다음 셀부터 이 그래프를 개선해 봐요!
g.plot.bar()
Out[89]:

unstack() 이해하기¶
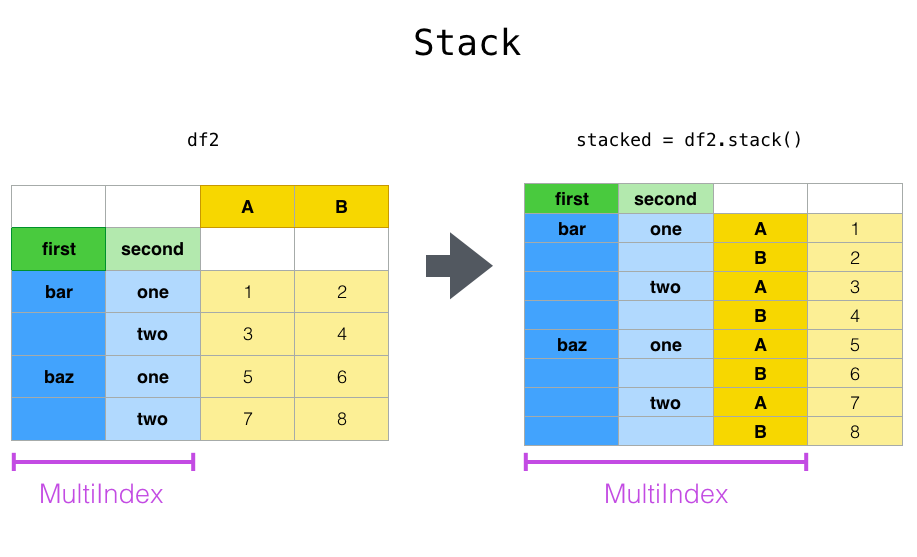
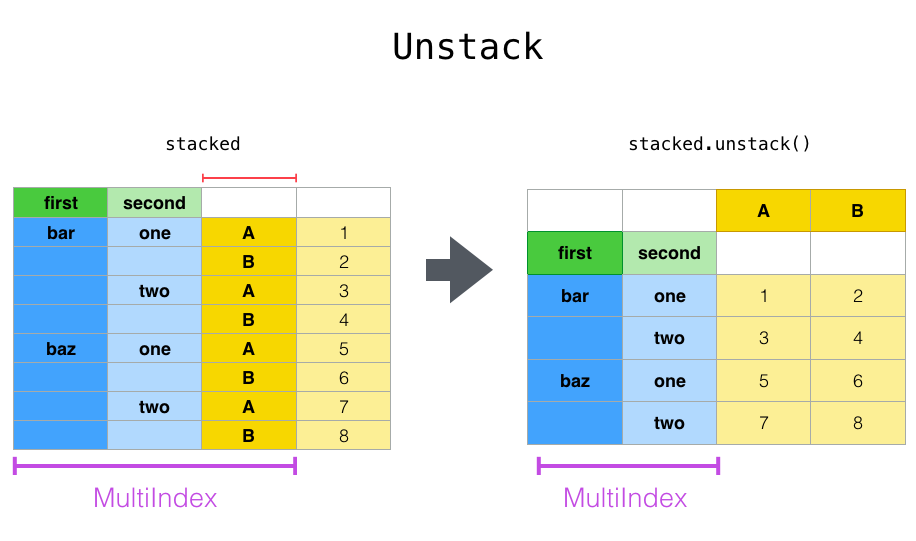
In [90]:
# 위에서 그룹화한 데이터를 unstack() 하고 iloc로 위에서 5개 왼쪽에서 5개만 서브셋을 봅니다.
g.unstack().iloc[:5, :5]
Out[90]:
In [91]:
# 그룹화된 결과에 unstack 을 사용하면 마지막 인덱스 컬럼이 컬럼으로 바뀝니다.
g.unstack().plot.barh(figsize=(8,9))
Out[91]:

In [92]:
# 구별로 학원 수 시각화 하기 unstack() 값에 transpose 를 하면 행과 열이 바뀝니다.
g.unstack().T.plot.bar(figsize=(15,5), rot=0)
Out[92]:

In [93]:
# 그룹화 한 값의 인덱스를 출력해 봅니다.
g.index
Out[93]:
In [115]:
# 멀티인덱스보다 컬럼으로 접근이 편하기 때문에 reset_index 를 통해 인덱스값을 컬럼으로 만들어 줍니다.
# "상호명" 컬럼은 "상호수" 이기 때문에 컬럼명을 변경해 줍니다.
t = g.reset_index()
t = t.rename(columns={"상호명":"상호수"})
t
Out[115]:
같은 그래프를 seaborn 으로 그리기¶
이미지 출처 : https://pandas.pydata.org/pandas-docs/stable/user_guide/reshaping.html
In [117]:
# x축에 시군구명을 y축에 상호수를 막대그래프로 그립니다.
# 상권업종소분류명 으로 색상을 다르게 표현합니다.
plt.figure(figsize = (15,4))
sns.barplot(data= t, x="시군구명", y="상호수", hue="상권업종소분류명")
Out[117]:

In [135]:
# x축에 상권업종소분류명을 y축에 상호수를 막대그래프로 그립니다.
# 시군구명 으로 색상을 다르게 표현합니다.
plt.figure(figsize = (15,4))
sns.barplot(data= t, x="상권업종소분류명", y="상호수", hue="시군구명")
Out[135]:

In [130]:
# "상권업종소분류명"이 "학원-입시" 인 서브셋만 가져와서 시각화 합니다.
academy_sub = t[t["상권업종소분류명"] == "학원-입시"].copy()
print(academy_sub.shape)
plt.figure(figsize=(15, 4))
sns.barplot(data=t, x="시군구명", y='상호수',ci=None)
Out[130]:

In [136]:
# catplot을 통해 서브플롯을 그립니다.
sns.catplot(data=t, x="상권업종소분류명", y="상호수", kind="bar",
col="시군구명", col_wrap=4, sharex=False)
Out[136]:

경도와 위도를 scatterplot 으로 표현하기¶
In [138]:
# scatterplot 으로 경도와 위도를 표현하고 시군구명으로 색상을 다르게 표현합니다.
plt.figure(figsize=(10, 7))
sns.scatterplot(data=df_academy_selected, x="경도", y="위도", hue="시군구명")
Out[138]:

In [139]:
# scatterplot 으로 경도와 위도를 표현하고 상권업종소분류명으로 색상을 다르게 표현합니다.
plt.figure(figsize=(10, 7))
sns.scatterplot(data=df_academy_selected, x="경도", y="위도", hue="상권업종소분류명")
Out[139]:

In [141]:
# "상권업종소분류명"이 "학원-입시" 인 데이터만 그려봅니다.
plt.figure(figsize=(10, 7))
sns.scatterplot(data= df_academy_selected[df_academy_selected["상권업종소분류명"] == "학원-입시"],
x="경도", y="위도", hue="상권업종소분류명")
Out[141]:

In [148]:
# "상권업종소분류명"이 "어린이집" 인 데이터만 그려봅니다.
plt.figure(figsize=(10, 7))
sns.scatterplot(
data=df_academy_selected[df_academy_selected["상권업종소분류명"] == "어린이집"],
x="경도", y="위도", hue="상권업종소분류명")
Out[148]:

In [149]:
# 어린이집과 학원-입시를 비교해 봅니다.
plt.figure(figsize=(10, 7))
sns.scatterplot(
data=df_academy_selected[
df_academy_selected["상권업종소분류명"].isin(["어린이집", "학원-입시"])],
x="경도", y="위도", hue="상권업종소분류명")
Out[149]:

In [154]:
# 어린이집과 학원-입시를 비교해 봅니다.
plt.figure(figsize=(10, 7))
sns.scatterplot(
data=df_academy_selected[(df_academy_selected["상권업종소분류명"] == "어린이집")|(df_academy_selected["상권업종소분류명"] == "학원-입시")],
x="경도", y="위도", hue="상권업종소분류명")
Out[154]:

In [156]:
# 위에서 그렸던 어린이집과 학원-입시에 대한 상호 데이터를 지도에 시각화 해봅니다.
#!pip install Folium
import folium
In [158]:
# 경도와 위도의 평균을 구해서 long, lat 변수에 담습니다.
long = df_academy_selected["경도"].mean()
lat = df_academy_selected["위도"].mean()
In [160]:
# "상권업종소분류명"에 "어린이집", "학원-입시"가 들어가는 데이터만 isin을 통해 가져옵니다.
df_m = df_academy_selected[
df_academy_selected["상권업종소분류명"].isin(["어린이집", "학원-입시"])]
df_m = df_m.sample(1000)
df_m.shape
Out[160]:
In [161]:
df_m.iloc[0]
Out[161]:
In [164]:
# folium 으로 Marker 를 지도로 표시해 봅니다.
m = folium.Map(location=[lat, long], zoom_start=12)
folium.Marker([37.5545, 126.867], tooltip="해법수학").add_to(m)
m
Out[164]:
In [165]:
# html 파일로 저장해 봅니다.
m.save('index.html')
In [166]:
# index 만 가져옵니다.
df_m.index
Out[166]:
In [167]:
# for문으로 데이터프레임을 순회하며 원하는 값을 가져옵니다.
for i in df_m.index[:10]:
tooltip = df_m.loc[i, "상호명"] +"-"+ df_m.loc[i, "도로명주소"]
lat = df_m.loc[i, "위도"]
long = df_m.loc[i, "경도"]
print(tooltip, lat, long)
In [168]:
# 위에서 작성해본 for문을 활용해 CircleMarker 로 표현해 봅니다.
m = folium.Map(location=[lat, long], zoom_start=12,
tiles='Stamen Toner')
for i in df_m.index[:100]:
tooltip = df_m.loc[i, "상호명"] +"-"+ df_m.loc[i, "도로명주소"]
lat = df_m.loc[i, "위도"]
long = df_m.loc[i, "경도"]
folium.CircleMarker([lat, long], tooltip=tooltip, radius=3).add_to(m)
m
Out[168]:
In [ ]:
댓글남기기